


Regresión Lineal: Manual práctico en Python
Regresión Lineal: Manual práctico en Python
Desde preparar los datos hasta leer el reporte de regresión.

En esta sección, crearemos una regresión con una base de datos pública, analizaremos el resultado que el reporte del software nos arroja y haremos pruebas a las hipótesis.
Piensa en este post como un cheat sheet (en México los llamamos “acordeones”, porque se hacían en hojitas de papel que se doblaban asemejando al instrumento musical) o un manual práctico para hacer regresiones lineales usando mínimos cuadrados ordinarios. Regresa aquí siempre que necesites.
Si hay algún término que te parezca extraño, recuerda que hicimos un par de posts con la teoría del modelo de mínimos cuadrados.
En este post
Aprende a importar y explorar la base de datos
Tips para limpiar los datos
Hacer una regresión por mínimos cuadrados
Aprende a leer el reporte de regresión que arroja `statsmodels`.
Paso 1. Explora la base de datos
Usaremos la base de datos de precios de casas de Kaggle para este ejercicio. Puedes descargarla directamente desde la página de Kaggle. El archivo de datos tendrá extensión *.csv, con variables separadas por comas.
En la sección "Data" de Kaggle hay cuatro archivos disponibles: uno es una descripción de los datos con información sobre cada columna. La base de datos que descargaremos tiene 81 columnas, y debemos identificar cuáles son útiles para describir los precios de las casas.
El archivo de prueba es igual al de entrenamiento, excepto que no incluye los precios. La idea es entrenar el modelo con la base de datos de entrenamiento y usar los parámetros obtenidos para predecir los precios en el archivo de prueba.
Paso 2: Importa los datos
Primero, importamos los datos de la base de entrenamiento. Luego, verificamos si hay valores nulos y los eliminamos o reemplazamos. También es importante convertir las variables categóricas a números para que puedan ser usadas en el modelo de regresión lineal.
El siguiente bloque de código carga la base de datos "/train.csv" utilizando la librería pandas y se muestra un resumen de los primeros registros con df.head().
# Módulos
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
# Cargar la base de datos
df = pd.read_csv("../data/house-prices/train.csv")
df.head()Aparte de **pandas** usaremos **statsmodels** para hacer la regresión y nos aseguramos de cargar las funciones que nos permiten escribir los modelos como una fórmula. Veremos eso más adelante.
El módulo pandas tiene una función que nos permite cargar los archivos csv. Lo que viene entre comillas del bloque anterior depende de en dónde se ubique tu archivo en la computadora. Cambia ese elemento y corre el código, te debería mostrar una tabla en pantalla con las primeras observaciones de la base de datos.
Primero, importamos los datos de la base de entrenamiento utilizando la librería pandas. Luego, verificamos si hay valores nulos y los eliminamos o reemplazamos. También es importante convertir las variables categóricas a números para que puedan ser usadas en el modelo de regresión lineal.
Usamos el módulo pandas para cargar la base de datos /train.csv y mostrar un resumen de los primeros registros con df.head(). Aparte de pandas, usamos statsmodels para hacer la regresión y nos aseguramos de cargar las funciones que nos permiten escribir los modelos como una fórmula.
El siguiente bloque de código carga la base de datos /train.csv y muestra un resumen de los primeros registros con df.head():
# Módulos
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
# Cargar la base de datos
df = pd.read_csv("../data/house-prices/train.csv")
df.head()La base de datos
Correr el código anterior genera una tabla similar a la que ves aquí en la pantalla, que muestra cómo se compone la base de datos.

Existen otros trucos para comprender mejor cómo es la base de datos. Si ejecutamos df.columns, Python nos mostrará una lista con los nombres de todas las columnas de la base de datos. Al ejecutar df.shape, el resultado nos indicará el número de filas y de columnas que contiene la tabla, respectivamente: en nuestro caso, la base de datos tiene 1460 filas y 81 columnas.
Por último, podemos usar df.describe() para generar un resumen descriptivo de los datos. Este resumen incluye el número de observaciones de cada variable. En la mayoría de los casos, ese número es 1.460, pero en algunos, los valores NA no se tienen en cuenta. Por eso, es importante prestar atención a este resumen.
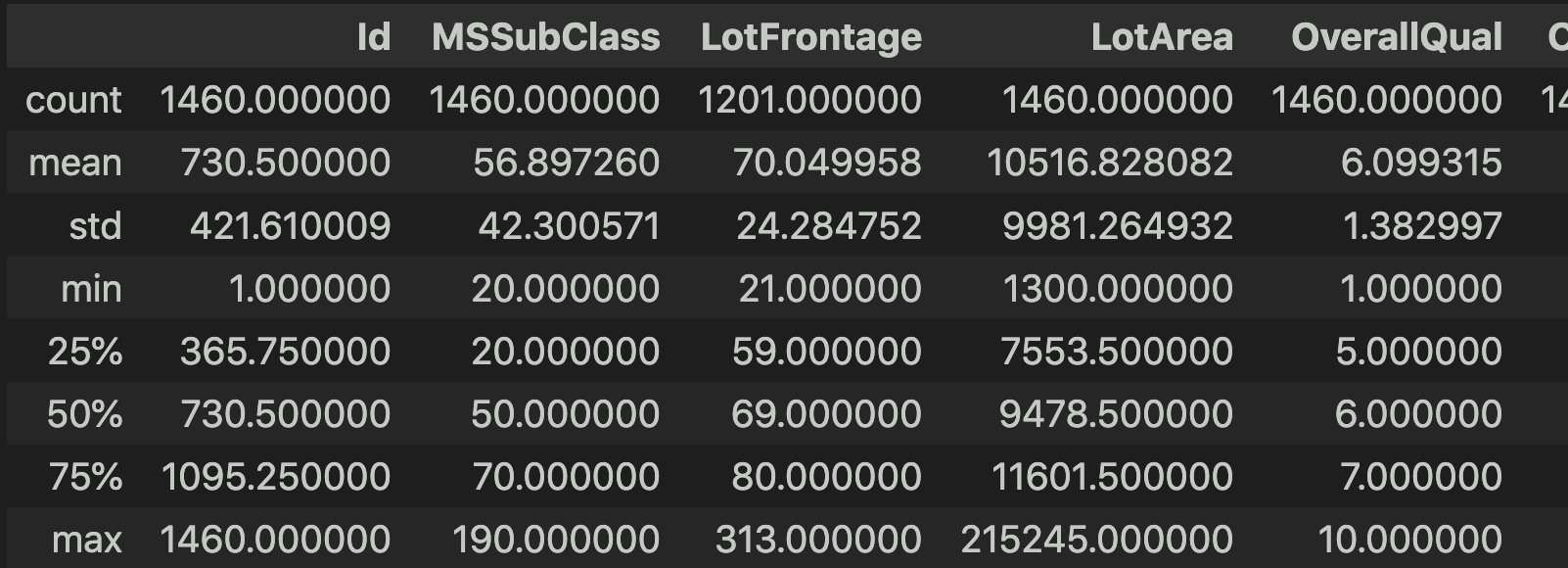
Existen otros trucos para comprender mejor cómo es la base de datos. Si ejecutamos df.columns, Python nos mostrará una lista con los nombres de todas las columnas de la base de datos. Al ejecutar df.shape, el resultado nos indicará el número de filas y de columnas que contiene la tabla, respectivamente: en nuestro caso, la base de datos tiene 1460 filas y 81 columnas.
Por último, podemos usar df.describe() para generar un resumen descriptivo de los datos. Este resumen incluye el número de observaciones de cada variable. En la mayoría de los casos, ese número es 1.460, pero en algunos, los valores NA no se tienen en cuenta. Por eso, es importante prestar atención a este resumen.
Recomendaciones sobre la limpieza de los datos
La base de datos no se toca. Antes de comenzar a hacer modificaciones, crea una copia de la base de datos y trabaja sobre la copia. En caso de que algo salga mal (y si deseas llegar a ser experto, algo va a salir mal), siempre puedes empezar de nuevo con la base de datos original. Puedes hacer una copia con el siguiente código.
# Hacer una copia de la base de datos
df2 = df.copy()
Verificar los valores nulos. Si existen valores nulos, reemplázalos con algún valor. Por ejemplo, si hay una variable con valores nulos, puedes reemplazarlos con la media de esa variable. Otra alternativa es eliminar las observaciones con valores nulos, pero es una decisión que hay que tomar con cuidado.
Convertir variables categóricas. Si hay variables categóricas, como por ejemplo "Tipo de vivienda" con valores como "Casa", "Apartamento" y "Cabaña", es necesario convertir esas variables a números para que el modelo las reconozca. El módulo
pandastiene una función para hacer esta conversión.
# Convertir variables categóricas a números
df2 = pd.get_dummies(df2, columns=["Tipo de vivienda"])
Eliminar variables irrelevantes. Si hay variables que no aportan ninguna información al modelo, como por ejemplo un número de identificación único, puedes eliminarlas. Esto ayuda a mejorar el rendimiento del modelo y evitar problemas como la multicolinealidad.
Una vez que has hecho los cambios apropiados a la base de datos, estamos listos para ejecutar la regresión.
Paso 3: Prepárate para la regresión
Para hacer nuestra regresión, el primer paso es diseñar el modelo. En nuestro caso, haremos un modelo que compara el precio de venta en función del área de los lotes. En otras palabras, esperamos que el modelo se comporte de la siguiente manera.
¿Es esto cierto? veamos cómo se vería un gráfico de nuestra base de datos. Ejecuta el siguiente bloque de código para generar un gráfico de dispersión.
import matplotlib.pyplot as plt
plt.scatter(df['LotArea'], df['SalePrice'], c = "#154954")
plt.show()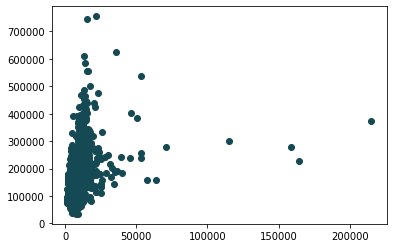
Este gráfico muestra en el eje horizontal el área de los lotes y en eje vertical los precios de venta. Desafortunadamente, ambas métricas tienen una distribución muy extensa. Las áreas de los lotes van desde 1,300 hasta 215 mil, que son esos puntos solitarios a la derecha.
Veremos un poco más sobre las transformaciones más adelante, pero algo muy práctico que podemos hacer para estos casos es transformar los datos a logaritmo. El siguiente bloque de código realiza la transformación en una copia de la base de datos y genera nuevas columnas transformadas con un logaritmo. El resultado muestra el grafico de nuestras variables transformadas.
import numpy as np
df2 = df.copy()
df2['LSalePrice'] = np.log(df2['SalePrice'])
df2['LLotArea'] = np.log(df2['LotArea'])
plt.scatter(df2['LLotArea'], df2['LSalePrice'], c = "#154954")
plt.show()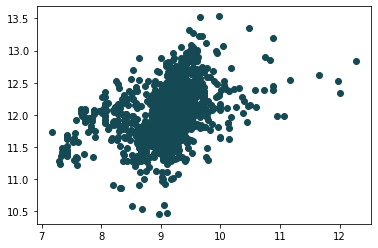
Este gráfico nos indica que los datos ahora “se comportan mejor” y aún seremos capaces de interpretarlos. Ahora si podemos hacer nuestra regresión.
Paso 4: Ejecuta la regresión
Haremos dos regresiones. La del modelo inicial que presentamos arriba y la del modelo transformado con logaritmos que transformamos y presentamos en gráfico.
Cuando la regresión es con una sola variable, es posible realizarla sin acudir a una fórmula. Basta usar la función OLS de statsmodels para generar nuestro reporte.
Ejecuta el siguiente bloque de código para que te aparezca un reporte como el que te muestro:
# Modelo de regresión
model = sm.OLS(df2['SalePrice'], df2['LotArea']).fit()
model.summary()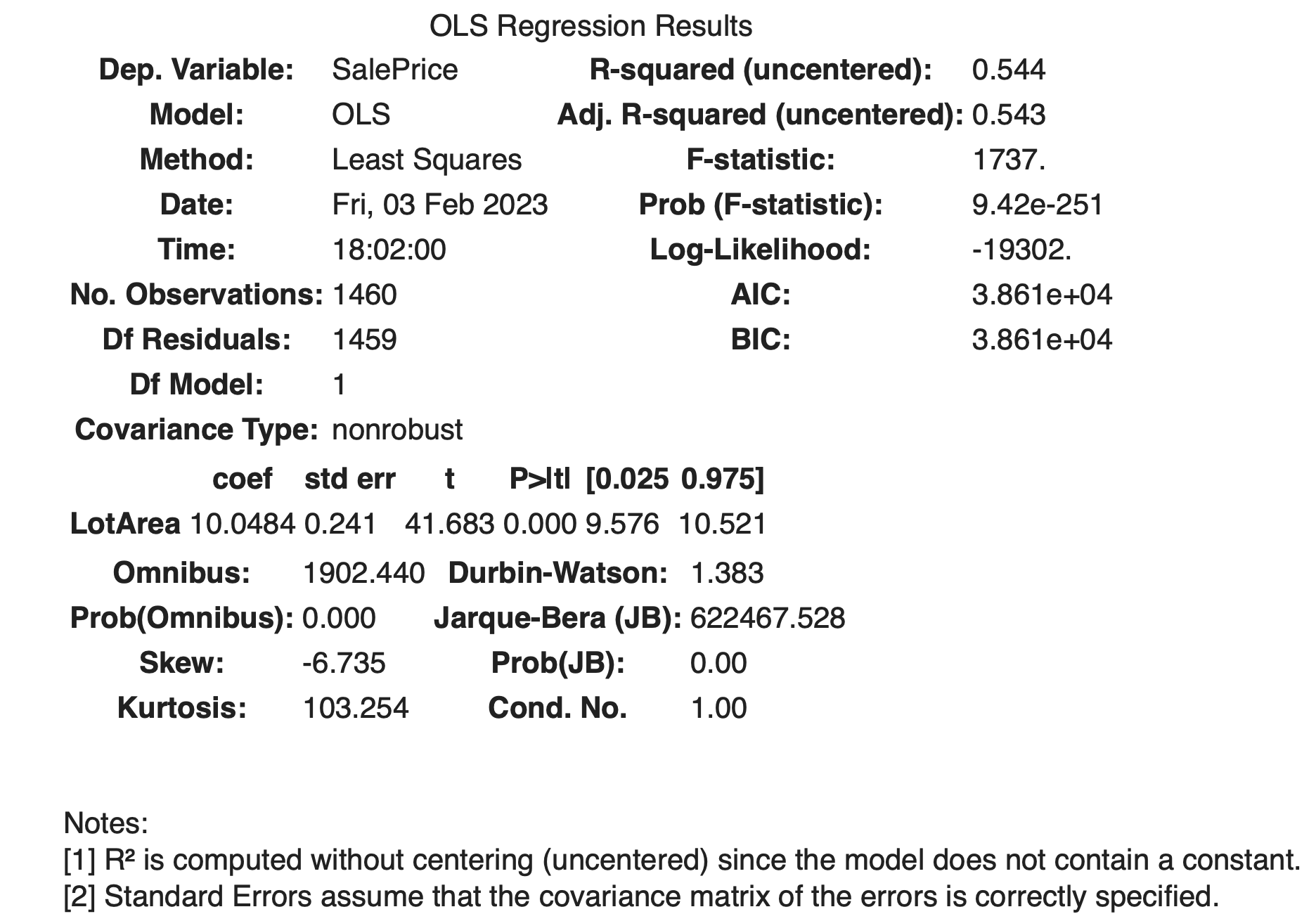
Paso 5: Cómo leer el reporte de regresión
Continúa leyendo con una prueba gratuita de 7 días
Suscríbete a Marionomics: Economía y Ciencia de Datos para seguir leyendo este post y obtener 7 días de acceso gratis al archivo completo de posts.