


Introducción al Modelo de Mínimos Cuadrados (Parte 1)
Introducción al Modelo de Mínimos Cuadrados (Parte 1)
Introducción al modelo más poderoso y la base de la econometría aplicada

Tenemos una variable dicotómica D, que puede tomar valores de 0 y 1 y proponemos la hipótesis de que esta variable afecta de alguna manera a nuestra variable de interés Y. Digamos que D_i es la exposición que tuvieron o no las personas a una campaña de marketing. Por lo tanto
La variable $Y_i$ es un indicador de las ventas que se generaron en la empresa en una observación.
Cuando decimos “una observación” es lo mismo a indicar una fila en la tabla. Por eso cuando tenemos $n$ observaciones, se dice que $i = {1,2,…, n}$, puede tomar cualquier valor del 1 a $n$.
Entonces, si deseamos conocer el efecto de nuestra campaña en las ventas, buscamos
Es decir, ¿cuál es el valor promedio de las ventas ceteris paribus, dada la exposición a nuestro anuncio?
El ceteris paribus (dejar todo lo demás constante) lo logramos incluyendo un vector de variables de control, representadas por $X$. Más adelante explicaremos cómo funciona.
También hemos incluido una variable que captura la aleatoriedad.
El modelo lineal
Nuestra mejor opción es comenzar con un modelo lineal como el siguiente:
En esta ecuación incluimos tres letras griegas. Por tradición, las letras griegas suelen representar parámetros, que son lo que deseamos calcular y son las que nos darán la respuesta a nuestras interrogantes.
Los parámetros en este modelo son $\beta_0$ (beta cero) y $\beta_1$ (beta uno). Nuestro objetivo es usar estos dos números para dibujar una línea en el plano cartesiano. Aquí, $\beta_0$ es el intercepto en el origen y $\beta_1$ la pendiente. La línea que dibujemos debería de ser la que mejor describe el comportamiento de nuestros datos.
Pero nuestros datos no vienen de una función matemática. No podemos esperar que se comporten como nuestro modelo dicta. Entonces cualquier línea que tracemos no cae directamente en los puntos. Para solventar este detalle definimos $\varepsilon$ (epsilon), que es un elemento estocástico o aleatorio. También se le conoce como término de error, y ayuda a explicar esa diferencia entre el punto de nuestros datos y la línea de regresión.
Haciendo regresión sobre una muestra
Normalmente los datos que tenemos a nuestra disposición son una muestra de la información existente. Por consecuencia, nuestra estimación no será exactamente aquella que obtendríamos si tuviéramos acceso a todos los datos. Esto es algo que tenemos que aceptar.
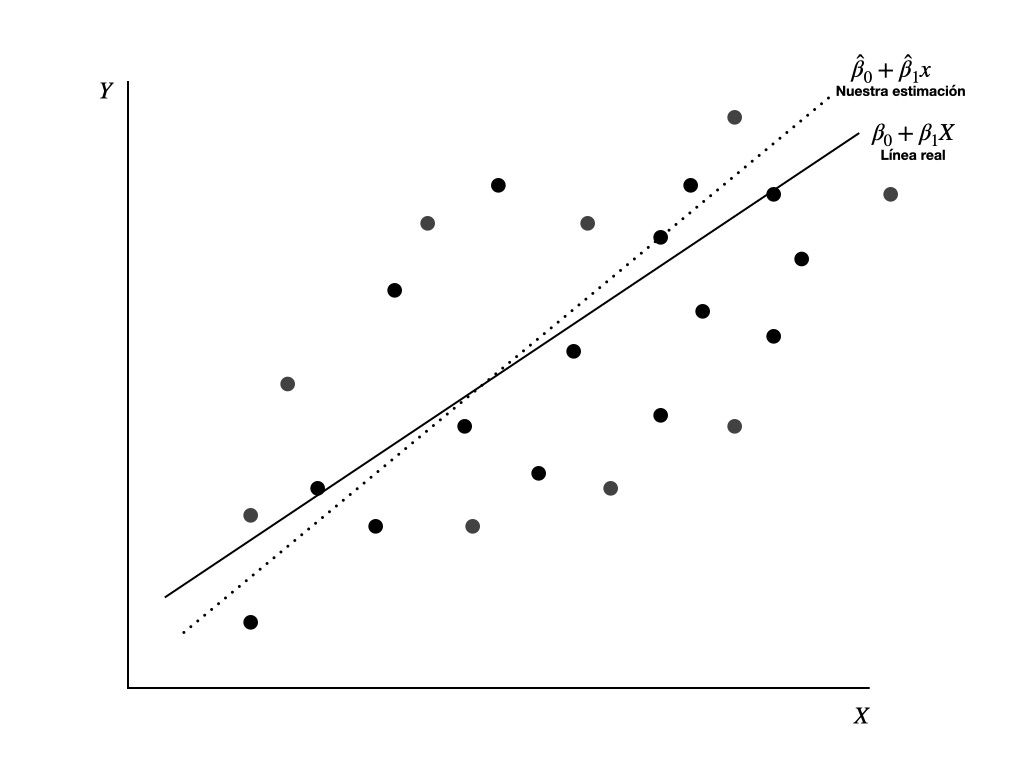
Este detalle genera un poco de notación adicional. Usamos el circunflejo para denotar cuando un parámetro viene de una estimación hecha sobre una muestra. Los parámetros de una muestra son entonces $\hat\beta_0$ y $\hat\beta_1$. Otro detalle es que usamos letras minúsculas para denotar cuando una variable es una muestra, por lo que usamos $x$ en lugar de $X$.
Continúa leyendo con una prueba gratuita de 7 días
Suscríbete a Marionomics: Economía y Ciencia de Datos para seguir leyendo este post y obtener 7 días de acceso gratis al archivo completo de posts.